This is the host site of the FIVR-200K dataset, which has been collected to simulate the problem of Fine-grained Incident Video Retrieval (FIVR). The dataset comprises 225,960 videos associated with 4,687 Wikipedia events and 100 selected video queries. Code to download the dataset and run the evaluation script can be found in the dataset's GitHub repo.
Presentation@ICME2020
Definitions
The Fine-grained Incident Video Retrieval (FIVR) is the problem where: given a query video, the objective is to retrieve all associated videos, considering several types of associations. Hence, FIVR offers a single framework that contains several retrieval tasks as special cases. In this work, three association types of related videos are considered:
- Duplicate Scene Videos (DSV): Videos that share at least one scene (captured by the same camera) regardless of any applied transformation.
- Complementary Scene Videos (CSV): Videos that contain part of the same spatio-temporal segment, but captured from different viewpoints.
- Incident Scene Videos (ISV): Videos that capture the same incident, i.e. they are spatially and temporally close, but have no overlap.
Dataset composition
For the collection of the FIVR-200K dataset, we set up the following process to retrieve videos about major news events that took place during the recent years. First, we crawled Wikipedia's Current Event page to build a collection of the major news events since the beginning of 2013. Each news event is associated with a topic, headline, text, date, and hyperlinks. Five examples of the collected news events are displayed on the following table.
| Headline | Date | Topic | Text | Source |
|---|---|---|---|---|
| Syrian civil war | 2013-01-01 | Armed conflicts and attacks | Fierce clashes erupt near the Aleppo ... | BBC |
| Greek debt crisis | 2015-07-07 | Business and economics | Eurozone leaders hold a crisis meeting ... | Reuters |
| Hurricane Harvey | 2017-08-29 | Disasters and accidents | The death toll from Hurricane Harvey ... | New York Times |
| Artificial intelligence | 2016-01-27 | Science and technology | A computer program called AlphaGo ... | MIT Technology Review |
| Boston Marathon Bombing | 2014-07-21 | Law and Crime | Azamat Tazhayakov, a friend of accused ... | MSN News |
We retained only news events categorized as "Armed conflicts and attacks" or "Disasters and accidents". We selected these two categories to find multiple videos on YouTube that report on the same news event, and ultimately to collect numerous pairs of videos that are associated with each other through the relations of interest (DSV, CSV and ISV). The time interval used for crawling the news events was from January 1st 2013 to December 31st 2017. A total of 9,431 news events were collected, and 4,687 news events were retained after filtering. Then, the public YouTube API was used to collect videos by providing event headlines as queries. The results were filtered to contain only videos published at the corresponding event start date and up to one week after the event. Furthermore, they were filtered to contain only videos with duration up to five minutes, which resulted in the collection of 225,960 videos (~48 videos/event).
For the automatic selection of the query videos, we had deployed a retrieval pipeline that estimated the suitability of candidate videos as benchmarks. A video graph is constructed by connecting with an edge the videos with high similarity score. The similarity between videos derives from the visual similarity of the video content and the textual similarity of the video titles. Then, the connected components of the video graph are extracted and filtered based on their size, the number of unique uploaders in the component, and the publication date of their videos. Attempting to find the original version of videos in each cluster, we chose the video that was published earliest as the query video. The total number of resulting queries using this process was 635. Since it would be overly time-consuming to annotate all of them, we selected the top 100 as the final query set (ranked based on the size of the corresponding graph component). In the following Figure, some examples of video queries and relevant videos for each association type from the FIVR-200K dataset are illustrated.









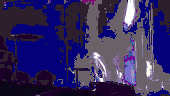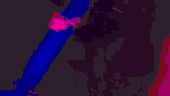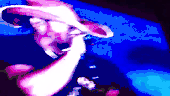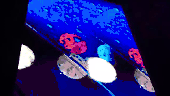




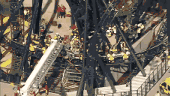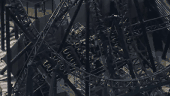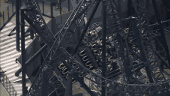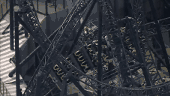
Annotation
The dataset annotations can be found here, where you can find the events crawled from Wikipedia (events.json), the video annotations (annotation.json) and the Youtube video ids (youtube_ids.txt).
The labels used for the annotation and their corresponding definitions are as follows:
- Near-Duplicate (ND): These are a special case of DSVs (all candidate scenes are duplicates with the query scenes).
- Duplicate Scene (DS): DSVs are annotated with this label.
- Complementary Scene (CS): CSVs are annotated with this label.
- Incident Scene (IS): ISVs are annotated with this label.
Citation
If you use FIVR-200K dataset in your research, please cite the following paper:
Contact
If you have any comment or encounter any issues, please get in touch with Giorgos Kordopatis-Zilos.
License and Acknowledgements

The content of this site is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0
(CC BY-NC-SA 4.0).
The video dataset is supported by the InVID and WeVerify projects, partially funded by the European Commission under contract numbers 687786 and 825297, respectively.